AWS S3 Multi-Part Uploads
Understanding multi-part uploads
Once you have created a bucket on AWS S31, you may want to transfer some data. It may so happen often that the data you want to transfer is very large, order of GB or even TBs.
AWS S3 allow you to create objects of upto 5TB in size, but the maximum you can upload via S3 put API is 5GB.
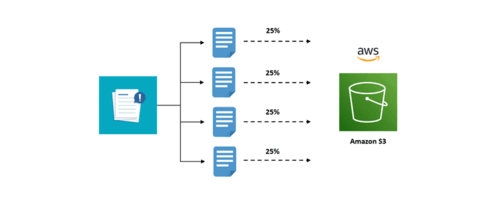
To allow you to upload bigger files, there is a concept called multi-part upload. This essentially means, we break the file we want to upload, then upload individual parts and allow S3 service to reassemble this to create the target file in the cloud. This makes the upload process resumable in cause of faults, and also faster as parts can be uploaded parallely.
Rules, rules and rules
Before diving into the code, there are some rules to remember when using the S3 multi-part upload API -
- A file can be split into a maximum of 10,000 parts.
- Each part needs to have a size between 5MB and 100MB.
Tip: You can use lifecycle policies to abort multipart uploads that take too much time
Steps for a multi-part upload
Broadly speaking, there are three basic steps to perform the upload -
- Register you multi-part upload via the
CreateMultipartUploadAPI, which gives you an UploadId in its response. - Then you upload individual parts using the
UploadPartAPI. Each upload responds back with an ETag.
Finally, when all uploads are finished, you make a call to CompleteMultipartUpload which requires the UploadID, PartNumbers and ETags to consolidate the file on cloud. Interesting thing to note is that it is possible to overwrite the individual parts when the uploads are being performed, this gives writer the ability to apply modifications to a very big file while the upload is in progress.
Hands-on
Get UploadID
We will use the create_multipart_upload function call.
For this aspect, we will create a handy function.
def start_upload(bucket, key):
"Returns the UploadId for multi-part upload"
client = boto3.client("s3")
response = client.create_multipart_upload(
Bucket = bucket,
Key = key
)
return response["UploadId"]
The function allows us to supply the bucket, key and get a UploadID for our upload process.
Upload one Part
We need a function to be able to upload one part for our upload. Later, we can use a multi-threading approach to upload in parallel.
def upload_part(bucket, key, part_num, upload_id, data):
"Upload a part to S3"
client = boto3.client("s3")
response = client.upload_part(
Bucket = bucket,
Key = key,
PartNumber = part_num,
UploadId = upload_id,
Body = data
)
print(f"Uploaded part {part_num} and received ETag {response['ETag']}")
return {
'PartNumber': part_num,
'ETag': response['ETag']
}
As you may notice, all function calls are self-explanatory. When we need to upload a specific part, we need to tell S3, what UploadID is it realted to, where it sits in the upload sequence, and what data are we uploading in this part.
Putting it together
To make everything work, we call the first funtion to get UploadID and use concurrent futures to upload multiple parts in parallel. Concurrent futures2 is a very handy library to quickly write code running on multiple threads or processes.
# Start upload
upload_id = start_upload(bucket, key)
# Upload parts
futures = []
with ProcessPoolExecutor(max_workers=10) as executor:
with open(file_name, "rb") as f:
i = 1
chunk = f.read(chunk_size_bytes)
while len(chunk) > 0:
future = executor.submit(upload_part, bucket=bucket, key=key, part_num=i, upload_id=upload_id, data=chunk)
futures.append(future)
i += 1
chunk = f.read(chunk_size_bytes)
results = []
for f in as_completed(futures):
results.append(f.result())
# Finalize the upload
response = boto3.client("s3").complete_multipart_upload(
Bucket = bucket,
Key = key,
UploadId = upload_id,
MultipartUpload = {
'Parts': sorted(results, key = lambda e: e["PartNumber"])
}
)
Finally, to test the program, you need to create a test bucket and a test file which is large enough for multi-part upload test.
# Create test bucket
aws s3 mb test-3224-random --region us-east-1
# Run program
python3 ./upload.py --file app.msi --bucket test-3224-random --key app.msi --chunk_size 6
Thats it, and it was that simple. Do leave comments for discussion and share if you like it!!
Solution code
In case you are missing part of the puzzle, below is the entire code for this exercise.
import boto3
import argparse
import json
import time
from concurrent.futures import ProcessPoolExecutor, wait, ALL_COMPLETED, as_completed
def start_upload(bucket, key):
"Returns the UploadId for multi-part upload"
client = boto3.client("s3")
response = client.create_multipart_upload(
Bucket = bucket,
Key = key
)
return response["UploadId"]
def upload_part(bucket, key, part_num, upload_id, data):
"Upload a part to S3"
client = boto3.client("s3")
response = client.upload_part(
Bucket = bucket,
Key = key,
PartNumber = part_num,
UploadId = upload_id,
Body = data
)
print(f"Uploaded part {part_num} and received ETag {response['ETag']}")
return {
'PartNumber': part_num,
'ETag': response['ETag']
}
if __name__ == '__main__':
MB = 1024 * 1024
# Read the file name
parser = argparse.ArgumentParser()
parser.add_argument("--file", required=True)
parser.add_argument("--bucket", required=True)
parser.add_argument("--key", required=True)
parser.add_argument("--chunk_size", required=True, help = "Size of individual parts in MB.")
args = parser.parse_args()
# Get args
file_name = args.file
bucket = args.bucket
key = args.key
chunk_size_bytes = int(args.chunk_size) * MB
# Start upload
upload_id = start_upload(bucket, key)
# Upload parts
futures = []
with ProcessPoolExecutor(max_workers=10) as executor:
with open(file_name, "rb") as f:
i = 1
chunk = f.read(chunk_size_bytes)
while len(chunk) > 0:
future = executor.submit(upload_part, bucket=bucket, key=key, part_num=i, upload_id=upload_id, data=chunk)
futures.append(future)
i += 1
chunk = f.read(chunk_size_bytes)
results = []
for f in as_completed(futures):
results.append(f.result())
# Finalize the upload
response = boto3.client("s3").complete_multipart_upload(
Bucket = bucket,
Key = key,
UploadId = upload_id,
MultipartUpload = {
'Parts': sorted(results, key = lambda e: e["PartNumber"])
}
)
print(json.dumps(response))

Leave a comment