
Apache Spark Unified Memory
Introduction
Apache Spark, a powerful distributed processing engine, relies heavily on memory management for optimal performance. The Unified Memory Manager (UMM) introduced in Spark 1.6 plays a critical role in this by efficiently allocating and managing memory resources across your cluster.
Understanding Memory Pools in Spark
Understanding concepts like reserved memory, executor memory, executor memory fraction, storage fraction, and overhead memory can help optimize memory usage and improve Spark application performance. The UMM manages two primary memory pools within the broader execution memory, storage and execution:
Storage Memory
This part of memory is used for storing RDDs when they are cached using persist and cache1, and also served to store broadcast2 data. You can tune this by using the config spark.executor.storage.fraction
Execution Memory
For certain data manipulations, spark needs to work on data like combining data using joins, sorting, aggregations etc. For performing this active computations, spark makes use of execution memory. Examples: In-memory joins, sorting and aggregations
In addition to the Unified Memory, we have other parts of memory reserved for internal processes, user objects etc.
Reserved and Overhead Memory
Overhead Memory
Overhead memory is additional memory required by each executor for off-heap memory, task execution, and other internal overheads. The default overhead memory is 384MB or 10% or executor memory whichever is higher, which is typically sufficient for most workloads.
Reserved Memory
Spark reserves a portion of the Unified Memory for internal metadata and other purposes not related to storage or execution. By default, Spark reserves 300MB of memory for these purposes.
Simple Example
Consider a Spark job running on a physical node with 20GB memory. Requesting an executor with spark.executor.memory = 10GB and spark.executor.offHeap.memory = 1GB would distribute the Spark executor’s container memory accordingly:.
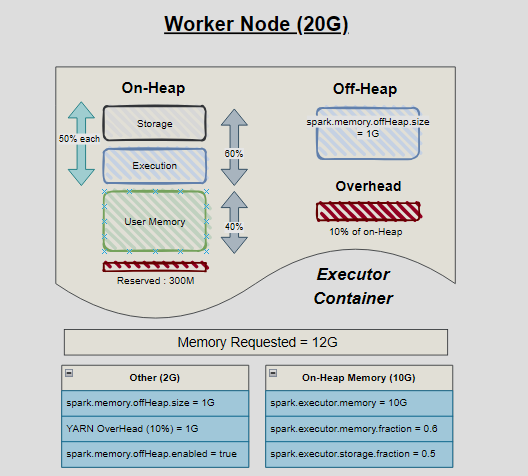
- Overheads (1G) - There are certain parts of memory that are required for managing JVM, Spark’s internal processes, Yarn’s processes. These are shown by red blocks and known as
reserved memory(used by spark) andoverhead(used by YARN). - On-Heap Memory (
spark.executor.memory = 10G) - This is JVM managed memory. Objects in on-heap are often garbage collected when needed, and this results in Garbage collection pauses. If you notice very high garbage collection times, then using off-heap memory is a good aid to the issue - Off-Heap Memory (
spark.executor.offHeap.memory = 1G) - This piece of memory resides outside control of JVM and is managed by the OS. Off-heap memory is disabled by default and is often used to reduce the garbage collection cycles
In case of On-heap memory, it is typically split into Unified Memory (Execution + Storage) memory, User Memory and Reserved. The amount of memory that goes to each depends on the below configs -
- Execution
spark.executor.memory.fraction (default 0.6)- Executor memory fraction is the ratio of Unified Memory that should be allocated to the execution memory pool. It is configured using the spark.memory.fraction property and defaults to 0.75, meaning that 75% of the Unified Memory is allocated to execution memory. - Storage
spark.executor.storage.fraction (default 0.5)- Storage fraction is the ratio of executor memory that should be used for storage purposes. It is configured using the spark.memory.storageFraction property and defaults to 0.5, meaning that 50% of the executor memory is allocated for storage.
Optimization Tips
- Tune Memory Fractions: Adjust the spark.executor.memory.fraction and spark.executor.storage.fraction configurations based on your workload to optimize memory allocation for execution and storage.
- Monitor and Tune: Regularly monitor memory usage and performance metrics to identify bottlenecks and adjust configurations accordingly.
- Use Efficient Data Structures: Use efficient data structures like DataFrames and Datasets, which can help reduce memory usage and improve performance.
Memory Calculator
Below is a simple Javascript interactive Diagram to help you understand how parameters affect the allocation of On-Heap memory.
Spark Memory Management Visualization
Conclusion
Understanding Apache Spark’s memory management is crucial for optimizing performance and avoiding memory-related issues. By understanding the different memory pools and how they are allocated, you can effectively tune your Spark applications for better performance.
-
Caching - While processing data, you can cache results of a time-consuming data process to ensure that this data is not recomputed if needed by downstream processes. Caching can speed up data pipelines that reuse data RDDs. ↩
-
Broadcast - Very useful when you want to perform table joins and one of the tables is small enough to be transferred over to every executor. This enables map side join, as data required for join is accessible in executor memory. ↩

Leave a comment